There are three modes where you can install Hadoop.
- Standalone - Everything run on one JVM under one single machine.
- Pseudo Distributed - Each run on it's own JVM under one machine.
- Fully Distributed - Each Service run on it's on machine.
I am using the following Ubuntu, JDK and Hadoop versions:
Hadoop version: hadoop-1.2.1
JDK: openjdk-7-jdk
Ubuntu: Server 14.04 LTS
Configuration and Installation Steps for Pseudo Distributed mode
Generate the public/private RSA key, without a password and save the key file with the default name "id_rsa.pub".
ssh-keygen
Add the generated key to authorized key list
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
For the Fully Distributed mode this key file needs to be send to each node through the "ssh-copy" to avoid password prompts.
Try SSH connect, it shouldn't ask for password
ssh localhost
Install Open JDK
sudo apt-get install openjdk-7-jdk
Check the java version after the installation is completed
java -version
Download the Hadoop
wget http://apache.mirrors.pair.com/hadoop/common/hadoop-1.2.1/hadoop-1.2.1-bin.tar.gz
Unpack the downloaded file
tar -zxvf hadoop-1.2.1-bin.tar.gz
Copy the unpacked files to directory " /usr/local/hadoop".
sudo cp -r hadoop-1.2.1 /usr/local/hadoop
Change the owner to current user
sudo chown mahesh /usr/local/hadoop
Add Hadoop bin directory path to the bashrc file, so you can run Hadoop any directory.
sudo vim $HOME/.bashrc
Go to the bottom of the file and add the following using a editor such as VIM.
export HADOOP_PREFIX=/usr/local/hadoop
export PATH=$PATH:$HADOOP_PREFIX/bin
Reload the script
exec bash
Check the whether the new path exists in the path variable
$PATH
Change JDK home and enable IP v4, Open following file (I have used the vim editor).
sudo vim /usr/local/hadoop/conf/hadoop-env.sh
Change highlighted lines
# Set Hadoop-specific environment variables here.
# The only required environment variable is JAVA_HOME. All others are
# optional. When running a distributed configuration it is best to
# set JAVA_HOME in this file, so that it is correctly defined on
# remote nodes.
# The java implementation to use. Required.
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-amd64
# Extra Java CLASSPATH elements. Optional.
# export HADOOP_CLASSPATH=
# The maximum amount of heap to use, in MB. Default is 1000.
# export HADOOP_HEAPSIZE=2000
# Extra Java runtime options. Empty by default.
export HADOOP_OPTS=-Djava.net.preferIPv4Stack=true
# Command specific options appended to HADOOP_OPTS when specified
export HADOOP_NAMENODE_OPTS="-Dcom.sun.management.jmxremote $HADOOP_NAMENODE_OPTS"
export HADOOP_SECONDARYNAMENODE_OPTS="-Dcom.sun.management.jmxremote $HADOOP_SECONDARYNAMENODE_OPTS"
Configure the name node by editing following file.
sudo vim /usr/local/hadoop/conf/core-site.xml
Add the highlighted section
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://mahesh-hd:10001</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
Create the temp directory
sudo mkdir /usr/local/hadoop/tmp
Change the owner to current user
sudo chown mahesh /usr/local/hadoop/tmp
Configure the MapReduce site
sudo vim /usr/local/hadoop/conf/mapred-site.xml
Add the highlighted section:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://mahesh-hd:10002</value>
</property>
</configuration>
Format the name node
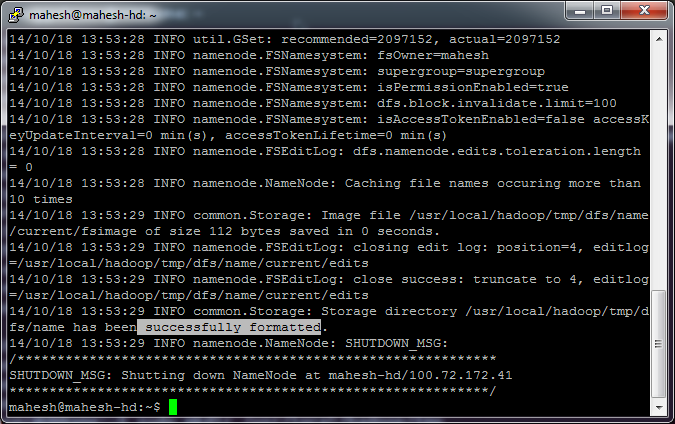
hadoop namenode -format
Following successful message should appear
Start all services using:
start-all.sh
Check whether all everything is running using "jps" command
Install Hadoop on Oracle JDK
Download and install Oracle JDK
sudo add-apt-repository ppa:webupd8team/java
sudo apt-get update
sudo apt-get install oracle-java7-installer
Change the hadoop-env.sh file java home directory according to the Oracle JDK path.



.jpg)

.jpg)






