
Sunday, December 21, 2014
Peer to Peer Lookup using Consistent Hashing and Virtual Nodes
It took a long time for me to understand the relationship between Consistent Hashing and Virtual Nodes.
Consitent Hashing and Virtual Nodes. Paper
Chord: A Scalable Peer-to-peer Lookup Service for Internet Applications
Consitent Hashing Paper
Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web
Amazon’s Dynamo DB uses consistent hashing with virtual nodes to locate nodes and keys in the dynamo ring.
Dynamo: Amazon’s Highly Available Key-value Store
Consitent Hashing and Virtual Nodes. Paper
Chord: A Scalable Peer-to-peer Lookup Service for Internet Applications
Consitent Hashing Paper
Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web
Consistent Hashing and Virtual Nodes
Amazon’s Dynamo DB uses consistent hashing with virtual nodes to locate nodes and keys in the dynamo ring.
Dynamo: Amazon’s Highly Available Key-value Store
Tuesday, November 18, 2014
Debug Hadoop Unit Test which runs on Maven
I am just running a single unit test
mvn -Dmaven.surefire.debug test -Dtest=org.apache.hadoop.hdfs.server.namenode.TestAddBlock
The tests will automatically pause and await a remote debugger on port 5005. You can then attach to the running tests using Eclipse.
Run > Debug Configarations

If you need to configure a different port, you may pass a more detailed value. For example, the command below will use port 8000 instead of port 5005.
mvn -Dmaven.surefire.debug="-Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=y,address=8000 -Xnoagent -Djava.compiler=NONE" test
Monday, November 17, 2014
CAP Theorem
In 2000, Eric Brewer published a paper stating that a Distributed system cannot
simultaneously provide all three of the following properties:

- Consistency: A read sees all previously completed writes.
- Availability: Reads (Actual Data) and writes always succeed.
- Partition tolerance: Guaranteed properties are
maintained even when network failures prevent some machines from
communicating with others.
Sunday, November 16, 2014
Run Haddop Unit Tests
Rull all the tests
mvn test
Run a single test
mvn test -Dtest=org.apache.hadoop.fs.TestSymlinkLocalFSFileContext
Run all the test even if there are errors
mvn -Dmaven.test.failure.ignore=true test
Run a single test even if there are errors
mvn -Dmaven.test.failure.ignore=true test -Dtest=org.apache.hadoop.fs.TestSymlinkLocalFSFileContext
mvn test
Run a single test
mvn test -Dtest=org.apache.hadoop.fs.TestSymlinkLocalFSFileContext
Run all the test even if there are errors
mvn -Dmaven.test.failure.ignore=true test
Run a single test even if there are errors
mvn -Dmaven.test.failure.ignore=true test -Dtest=org.apache.hadoop.fs.TestSymlinkLocalFSFileContext
Basic Git Commands
Get a copy of specific repository branch to the local computer
git clone -b [branch name] https://github.com/[namespace]/[project].git
Initializes and push a new project to GitHub
git init
git add .
git commit -m "first commit"
git remote add origin https://github.com/[namespace]/[project].git
git push -u origin master
Reset all the local repository changes to Head.
git reset --hard
Show the working tree status
git status
git clone -b [branch name] https://github.com/[namespace]/[project].git
Initializes and push a new project to GitHub
git init
git add .
git commit -m "first commit"
git remote add origin https://github.com/[namespace]/[project].git
git push -u origin master
Reset all the local repository changes to Head.
git reset --hard
Show the working tree status
git status
Monday, November 10, 2014
Hide current working directory in Ubuntu Terminal
Just type below command in the Terminal.
export PS1='\u@\h:~$ '
Add above command to the bashrc file, so you do not have to type in the command again every time you load a new terminal.
sudo vi $HOME/.bashrc
Go to the bottom of the file and add the following using a editor such as VI.
export PS1='\u@\h:~$ '
Saturday, November 8, 2014
Compile Hadoop Trunk on Ubuntu
Prerequisites
Install JDK
How to Install Oracle Java7 in Ubuntu Server 14.04 LTS
Install Maven
Install Maven on Ubuntu
Check if the ProtocolBuffers already installed?
protoc --version
Install ProtocolBuffers
sudo apt-get install protobuf-compiler
Check the version
protoc --version
if the version does not display try following command.
sudo ldconfig
protoc --version
I have downloaded the "hadoop-trunk.zip" from Git Hub.
if you want after the extract copy the hadoop-trunk directory to your project working area.
sudo cp -r hadoop-trunk /home/mahesh/projects/hadoop/hadoop-trunk
Change the ownership of the hadoop-trunk direcoty to you. This should be done with '-R' (Recursive)
sudo chown -R mahesh hadoop-trunk
Compile Hadoop
mvn install -DskipTests
If everything goes well you should see "BUILD SUCCESSFUL" message. Build would take a while to complete depending on you Internet connection speed, since Maven will download all the required artifacts in the first build.

mvn eclipse:eclipse -DdownloadSources=true -DdownloadJavadocs=true

Install JDK
How to Install Oracle Java7 in Ubuntu Server 14.04 LTS
Install Maven
Install Maven on Ubuntu
Check if the ProtocolBuffers already installed?
protoc --version
Install ProtocolBuffers
sudo apt-get install protobuf-compiler
Check the version
protoc --version
if the version does not display try following command.
sudo ldconfig
protoc --version
I have downloaded the "hadoop-trunk.zip" from Git Hub.
if you want after the extract copy the hadoop-trunk directory to your project working area.
sudo cp -r hadoop-trunk /home/mahesh/projects/hadoop/hadoop-trunk
Change the ownership of the hadoop-trunk direcoty to you. This should be done with '-R' (Recursive)
sudo chown -R mahesh hadoop-trunk
Compile Hadoop
mvn install -DskipTests
If everything goes well you should see "BUILD SUCCESSFUL" message. Build would take a while to complete depending on you Internet connection speed, since Maven will download all the required artifacts in the first build.
mvn eclipse:eclipse -DdownloadSources=true -DdownloadJavadocs=true
'protoc --version' did not return a version
I came across this error while I was triying to Build Hadoop.

Check if the ProtocolBuffers already installed?
protoc --version
Install ProtocolBuffers
sudo apt-get install protobuf-compiler
Check the version
protoc --version

if the version does not display try following command.
sudo ldconfig
protoc --version
The above steps should fix the issue. But while i was trying to figure out the issue I installed the following as well.
I got the above command from HowToContribute but i changed it.
I removed the "maven build-essential" from the command. since this will configure the Ubuntu with Open JDK and other tools which is not required.
Further Details can found in the following URI.
Trunk doesn't compile
Check if the ProtocolBuffers already installed?
protoc --version
Install ProtocolBuffers
sudo apt-get install protobuf-compiler
Check the version
protoc --version
if the version does not display try following command.
sudo ldconfig
protoc --version
The above steps should fix the issue. But while i was trying to figure out the issue I installed the following as well.
apt-get -y install autoconf automake libtool cmake zlib1g-dev pkg-config libssl-dev
I got the above command from HowToContribute but i changed it.
apt-get -y install maven build-essential autoconf automake libtool cmake zlib1g-dev pkg-config libssl-dev
I removed the "maven build-essential" from the command. since this will configure the Ubuntu with Open JDK and other tools which is not required.
Further Details can found in the following URI.
Trunk doesn't compile
Install Maven on Ubuntu
Download and extract Maven.
Add Maven bin directory path to the bashrc file, so you can run Maven from any location.
sudo vi $HOME/.bashrc
Go to the bottom of the file and add the following using a editor such as VI.
export M2_HOME=/usr/local/apache-maven-3.2.3
export PATH=$PATH:$M2_HOME/bin
Make sure JDK path is also set
export JDK_PREFIX=/usr/local/jdk1.7.0_71
export PATH=$PATH:$JDK_PREFIX/bin
Add Maven bin directory path to the bashrc file, so you can run Maven from any location.
sudo vi $HOME/.bashrc
Go to the bottom of the file and add the following using a editor such as VI.
export M2_HOME=/usr/local/apache-maven-3.2.3
export PATH=$PATH:$M2_HOME/bin
Make sure JDK path is also set
export JDK_PREFIX=/usr/local/jdk1.7.0_71
export PATH=$PATH:$JDK_PREFIX/bin
Monday, November 3, 2014
ssh connect to host localhost port 22 connection refused ubuntu
Use the following command
sudo apt-get remove openssh-client openssh-server More details Why am I getting a “port 22: Connection refused” error? Monday, October 27, 2014
Installing Apache Hardtop on Multi Node Fully Distributed Cluster
Create Virtual Machine Template
Build the initial VM by following the my blob post: Installing Apache Hadoop on a Single Node .
Follow the steps in the below Windows Azure article:
How to Capture a Linux Virtual Machine to Use as a Template
Create Five Node Cluster on Windows Azure
Virtual Machine 1 : Name Node and Job Tracker
Virtual Machine 2 : Secondary Name Node
Virtual Machine 3 : Data Node 1
Virtual Machine 4 : Data Node 2
Virtual Machine 5 : Data Node 3
Enable Localhost SSH
ssh-keygen -f "/home/mahesh/.ssh/known_hosts" -R localhost
Change the yellow highlighted text with your user name.
Copy SSH Key to each machine from the Name Node
ssh-copy-id -i $HOME/.ssh/id_rsa.pub mahesh@hd-name2
ssh-copy-id -i $HOME/.ssh/id_rsa.pub mahesh@hd-data1
ssh-copy-id -i $HOME/.ssh/id_rsa.pub mahesh@hd-data2
ssh-copy-id -i $HOME/.ssh/id_rsa.pub mahesh@hd-data3
If you get the error "/usr/bin/ssh-copy-id: ERROR: ssh: Could not resolve hostname hd-name2: Name or service not known". Change host name to the IP.
And if you happened to use the IP, change host namer of "/usr/local/hadoop/conf/core-site.xml" and "/usr/local/hadoop/conf/mapred-site.xml" to IP of the Name Node.
Update "Masters" configuration file with Secondary Name node IP
sudo vi /usr/local//hadoop/conf/masters
Update "Slaves" configuration file with Data node IPs (Each IP should be entered as a new line)
sudo vi /usr/local//hadoop/conf/slaves
Format the name node
hadoop namenode -format
Start Name, Secondary Name Node and Data Nodes
start-dfs.sh

start-mapred.sh

Sunday, October 19, 2014
How to Install Oracle Java7 in Ubuntu Server 14.04 LTS
Add the webupd8team repository
sudo add-apt-repository ppa:webupd8team/java
Get package list
sudo apt-get update
Download and Install the Oracle java 7
sudo apt-get install oracle-java7-installer
Verify the installation
java -version
Or else you can download the JDK from Oracle site. for example " dk-7u71-linux-x64.tar.gz"
Extract it the compressed JDK package
Add JDK bin directory path to the bashrc file, so you can run JDK from any location.
sudo vi $HOME/.bashrc
export JDK_PREFIX=/usr/local/jdk1.7.0_71
export PATH=$PATH:$JDK_PREFIX/bin
sudo add-apt-repository ppa:webupd8team/java
Get package list
sudo apt-get update
Download and Install the Oracle java 7
sudo apt-get install oracle-java7-installer
Verify the installation
java -version
Or else you can download the JDK from Oracle site. for example " dk-7u71-linux-x64.tar.gz"
Extract it the compressed JDK package
Add JDK bin directory path to the bashrc file, so you can run JDK from any location.
sudo vi $HOME/.bashrc
export JDK_PREFIX=/usr/local/jdk1.7.0_71
export PATH=$PATH:$JDK_PREFIX/bin
Saturday, October 18, 2014
Installing Apache Hadoop on a Single Node
There are three modes where you can install Hadoop.
- Standalone - Everything run on one JVM under one single machine.
- Pseudo Distributed - Each run on it's own JVM under one machine.
- Fully Distributed - Each Service run on it's on machine.
I am using the following Ubuntu, JDK and Hadoop versions:
Hadoop version: hadoop-1.2.1
JDK: openjdk-7-jdk
Ubuntu: Server 14.04 LTS
Hadoop version: hadoop-1.2.1
JDK: openjdk-7-jdk
Ubuntu: Server 14.04 LTS
Configuration and Installation Steps for Pseudo Distributed mode
Generate the public/private RSA key, without a password and save the key file with the default name "id_rsa.pub".ssh-keygen
Add the generated key to authorized key list
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
For the Fully Distributed mode this key file needs to be send to each node through the "ssh-copy" to avoid password prompts.
Try SSH connect, it shouldn't ask for password
ssh localhost
Install Open JDK
sudo apt-get install openjdk-7-jdk
Check the java version after the installation is completed
java -version
Download the Hadoop
wget http://apache.mirrors.pair.com/hadoop/common/hadoop-1.2.1/hadoop-1.2.1-bin.tar.gz
Unpack the downloaded file
tar -zxvf hadoop-1.2.1-bin.tar.gz
Copy the unpacked files to directory " /usr/local/hadoop".
sudo cp -r hadoop-1.2.1 /usr/local/hadoop
Change the owner to current user
sudo chown mahesh /usr/local/hadoop
Add Hadoop bin directory path to the bashrc file, so you can run Hadoop any directory.
sudo vim $HOME/.bashrc
Go to the bottom of the file and add the following using a editor such as VIM.
export HADOOP_PREFIX=/usr/local/hadoop
export PATH=$PATH:$HADOOP_PREFIX/bin
Reload the script
exec bash
Check the whether the new path exists in the path variable
$PATH
Change JDK home and enable IP v4, Open following file (I have used the vim editor).
sudo vim /usr/local/hadoop/conf/hadoop-env.sh
Change highlighted lines
# Set Hadoop-specific environment variables here.
# The only required environment variable is JAVA_HOME. All others are
# optional. When running a distributed configuration it is best to
# set JAVA_HOME in this file, so that it is correctly defined on
# remote nodes.
# The java implementation to use. Required.
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-amd64
# Extra Java CLASSPATH elements. Optional.
# export HADOOP_CLASSPATH=
# The maximum amount of heap to use, in MB. Default is 1000.
# export HADOOP_HEAPSIZE=2000
# Extra Java runtime options. Empty by default.
export HADOOP_OPTS=-Djava.net.preferIPv4Stack=true
# Command specific options appended to HADOOP_OPTS when specified
export HADOOP_NAMENODE_OPTS="-Dcom.sun.management.jmxremote $HADOOP_NAMENODE_OPTS"
export HADOOP_SECONDARYNAMENODE_OPTS="-Dcom.sun.management.jmxremote $HADOOP_SECONDARYNAMENODE_OPTS"
Configure the name node by editing following file.
sudo vim /usr/local/hadoop/conf/core-site.xml
Add the highlighted section
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://mahesh-hd:10001</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
Create the temp directory
sudo mkdir /usr/local/hadoop/tmp
Change the owner to current user
sudo chown mahesh /usr/local/hadoop/tmp
sudo vim /usr/local/hadoop/conf/mapred-site.xml
Add the highlighted section:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://mahesh-hd:10002</value>
</property>
</configuration>
Format the name node
hadoop namenode -format
Following successful message should appear
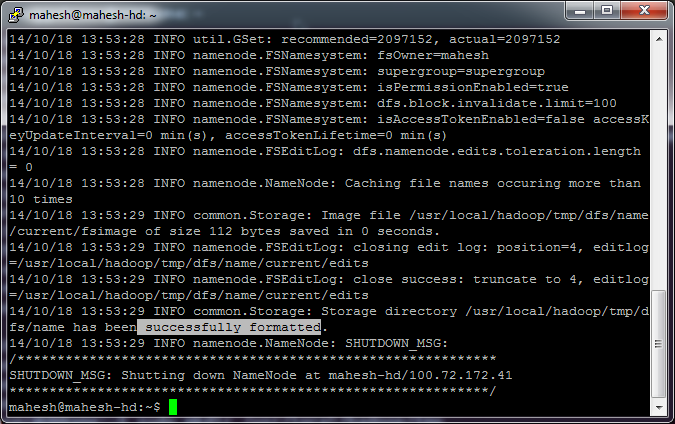
Start all services using:
start-all.sh

Install Hadoop on Oracle JDK
Download and install Oracle JDKsudo add-apt-repository ppa:webupd8team/java
sudo apt-get update
sudo apt-get install oracle-java7-installer
Change the hadoop-env.sh file java home directory according to the Oracle JDK path.
A Lion Called Christian
This was a story about a lion cub who was bought by two Australians (Ace and John) from Harrods department store. They called him Christian.
.jpg)

.jpg)
As the Christian grew bigger they arraigned Christian to be returned to the wild in Kenya.
Below images shows two unforgettable Christian's reunion with the Ace and John. The first reunion was made after almost 2 years after Christian was returned to the wild.
Second reunion.
Sunday, October 12, 2014
Achieving Rapid Response Times in Large Online Services - Google
When a query comes in there is a whole bunch of sub systems needs to be used in order to generate the information they needs on surface of the page. So they break these large systems down into bunch of sub services, and they need enough computation power on the back end so eventually when they get a query in and hit thousands of server and get all the results back and decide what they gonna show to the user in a pretty short amount of time.

In Google all of these servers run on shared environment, they do not allocate a particular machine for a specific task.

To handle this they take a little bit of a latency hit in order to keep the serving system safe. What they do they send the query to just a one leave and if that succeed then they have more confidence that query to gonna trouble sending to all thousand servers.

Source:https://www.youtube.com/watch?v=1-3Ahy7Fxsc
In Google all of these servers run on shared environment, they do not allocate a particular machine for a specific task.
Canary Requests
One of the ways to keeping your serving system safe in the presence of a large fanout system. normally when you take in a query on top of the tree and send it down to the parents eventually to all the leaves. What happens if all of the sudden the query passing code runs on leaves crash for some reason, due to a weird property of the query never seen before. so all of the sudden you send the query down and it will kill your data center.To handle this they take a little bit of a latency hit in order to keep the serving system safe. What they do they send the query to just a one leave and if that succeed then they have more confidence that query to gonna trouble sending to all thousand servers.
Backup Request
Request (req 9 ) is sent to particular server and if they do not heard back from that server, the send the same request to a another server.Source:https://www.youtube.com/watch?v=1-3Ahy7Fxsc
Wednesday, October 8, 2014
Did George Mallory lead the first successful attempt on the summit of Everest?
It’s a primitive attempt, to do a huge undertaking. He had
to rely on human spirit alone not on technology. He just had only his heart and
soul.
He was born in 1886. He married Ruth Turner in 1914.

He was invited to Everest expeditions on 1921, 1922 and 1924.
He was the only climber who was being on all three expeditions.
it was his last chance to have an attempt on Everest, he knew
that since at the age of 38 he would not
have high chance of getting selected to another expedition. He was in for an all-out
effort on that final day. He was in the mindset that it’s all or nothing in
that day.
He chose Andrew Irvine who was the youngest member of the
expedition to join him on final attempt on the summit. Irvine had little
experience as a climber but he was skilled with maintaining oxygen equipment’s.

Noel Odell was last person who saw Mallory and Irvine alive,
he saw them shortly after mid-day on 8th of June 1924, just a few hundred
feet from the summit at 28400 Ft and still going strong for the top. Clouds
then rolled in and they were never seen again.
Mallory’s body was found during an expedition in 1999, 75 years
after they lost. Surprisingly most of the belongings were well preserved and
intact. They found his goggles in his pocket that meant he was climbing down
after the sun. So they are assuming from that they are coming down when they fell. One very significant item was missing the photo of his wife Ruth
which he had promised to leave on the summit as ultimate tribute to his love of
Ruth. Was the photo missing that the Mallory had reached the summit and placed
it there. This really tells that might have fallen during the descent.
Mountaineers believe that Mallory could have climbed even with
the standards of mountain climbing during 1924 are very primitive. Just enough
of wild man that he might just had a good day and pulled it off.
Tuesday, October 7, 2014
Why Hadoop is Required
When you have massive loads of data in a RDMS, you usually aggregate raw data and most of the time you move the raw data into a different storage or delete them. So the problem is that when in some point when you want to access that Raw data, there could be two things it very time consuming or not possible.
In some companies have their Raw data in files and they have ETL (Extract, transform, load) tools to aggregate and load them into to a RDMS, This process makes a huge stress on network layer since the data from the file stores has to move into the ETL tool for processing, through the network. Once the data is aggregated it is moved to a achieve location. The archived data retrieval is very slow process as well if some one wants read the raw data again.
So there are three problems:
How the RDMS process data

Hadoop does not get the data to the computation engine through the network instead it keeps the computation Just Next to the Data.

Each server is processing independently it's local data.
In some companies have their Raw data in files and they have ETL (Extract, transform, load) tools to aggregate and load them into to a RDMS, This process makes a huge stress on network layer since the data from the file stores has to move into the ETL tool for processing, through the network. Once the data is aggregated it is moved to a achieve location. The archived data retrieval is very slow process as well if some one wants read the raw data again.
So there are three problems:
- Cannot access Raw high fidelity data
- Computation cannot scale (Since all the data should be taken into the computation engine through the network)
- To avoid stress on computation, the old data needs to be archived, and once they are achieved it is an expensive process to access them again.
How the RDMS process data
Hadoop does not get the data to the computation engine through the network instead it keeps the computation Just Next to the Data.
Each server is processing independently it's local data.
Thursday, July 24, 2014
Overview of Hadoop
Hadoop is an open source cloud computing platform of the Apache Foundation that provides a software programming framework called MapReduce and distributed file system, HDFS (Hadoop Distributed File
System). Hadoop is a Linux based set of tools that uses commodity hardware. Hadoop project was stared by Doug Cutting.The main usage of Hadoop is to store massive amount of data in the HDFS and perform the analytics of the stored data using MapReduce programming model.
System). Hadoop is a Linux based set of tools that uses commodity hardware. Hadoop project was stared by Doug Cutting.The main usage of Hadoop is to store massive amount of data in the HDFS and perform the analytics of the stored data using MapReduce programming model.
Monday, July 21, 2014

Wednesday, April 9, 2014
Setting up ANT on Windows
1) Download the ANT from Apache.
2) Extract the .zip file to a directory near to root
D:\apache-ant-1.9.3
3) Set following environment variables according to your directory structure.
ANT_HOME=D:\apache-ant-1.9.3
JAVA_HOME=D:\Program Files\Java\jdk1.7.0_45
PATH=D:\cygwin64\bin;%ANT_HOME%\bin;
if the PATH variable contains already contains paths. separate them with ";".

Every time a change is made to the environmental variables get a new command prompt. type the following two commands in the CMD to check whether the ANT is working properly

You will get an error since you have not passed a build XML for the first command.
2) Extract the .zip file to a directory near to root
D:\apache-ant-1.9.3
3) Set following environment variables according to your directory structure.
ANT_HOME=D:\apache-ant-1.9.3
JAVA_HOME=D:\Program Files\Java\jdk1.7.0_45
PATH=D:\cygwin64\bin;%ANT_HOME%\bin;
if the PATH variable contains already contains paths. separate them with ";".
Every time a change is made to the environmental variables get a new command prompt. type the following two commands in the CMD to check whether the ANT is working properly
You will get an error since you have not passed a build XML for the first command.
Subscribe to:
Comments (Atom)